
Table of Contents
- Introduction
- Understanding Python UnicodeDecodeError fix
- What is UnicodeDecodeError?
- Why Does UnicodeDecodeError Happen?
- Best Python UnicodeDecodeError Fixes
- Specify the Correct Encoding
- Use
errors="replace"orerrors="ignore" - Detect Encoding Automatically
- Convert File Encoding
- Handle Byte Data Correctly
- Use
ftfyfor Text Normalization - Utilize
codecsfor File Handling - Implement Universal Encoding Practices
- Common Real-World Scenarios of UnicodeDecodeError
- How to Prevent UnicodeDecodeError in the Future
- Conclusion
- FAQs on Python UnicodeDecodeError Fix
Introduction
Are you struggling with UnicodeDecodeError in Python? This error occurs when Python attempts to decode a byte sequence using an incorrect encoding. If you’re dealing with text files, data scraping, or file conversions, understanding how to handle encoding errors is essential to avoid script failures.
In this guide, you’ll learn how to fix python UnicodeDecodeError fix , explore best practices for handling encoding, and discover tools to prevent future issues. We’ll cover detailed explanations, code examples, and expert tips to ensure smooth Python development.
📌Related Posts:
- 7 Fixes for Why Is My Python Code Not Running?
- Python Crash Fix: 7 Solutions for Jupyter & Spyder Issues
- 10 Proven Ways to Debugging Python in PyCharm and VS Code
- How to Install Python: Easy Setup Guide for Beginners
- How to Fix Python Installation and Compatibility Issues in Conda and Pip
Understanding Python UnicodeDecodeError
What is UnicodeDecodeError?
A UnicodeDecodeError occurs when Python encounters an incompatible byte sequence while decoding text. This typically results from opening a file with an incorrect encoding assumption.
Python uses Unicode for text representation, but files and external data sources often use different encodings like UTF-8, ASCII, or ISO-8859-1. When there’s a mismatch between the file encoding and the specified encoding in Python, this error occurs.
Common Error Message:

Why Does UnicodeDecodeError Happen?
Several reasons lead to this error:
- Incorrect Encoding Assumption – Reading a non-UTF-8 file as UTF-8.
- Non-ASCII Characters – Presence of symbols like é, ñ, ü, or special characters.
- File Corruption – Data conversion issues during file transfers.
- Mixed Encodings in a File – Some files contain multiple encoding formats.
- Incomplete File Reads – Reading a binary file as text without proper decoding.
- System-Specific Encoding Differences – Different operating systems may use different default encodings.
Understanding the root cause of this error is essential to apply the correct fix.
Best Python UnicodeDecodeError Fixes
1. Specify the Correct Encoding When Reading Files
Explicitly defining encoding can resolve many issues. UTF-8 is the most commonly used encoding and should be set when opening files.
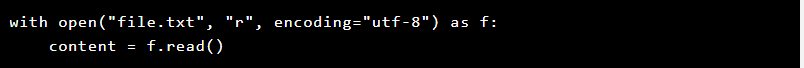
If you suspect a different encoding, try ISO-8859-1 or Windows-1252.

2. Use errors="replace" or errors="ignore" to Avoid Crashes
Sometimes, files contain characters that cannot be decoded with the specified encoding. You can handle these errors gracefully by replacing or ignoring problematic characters.
3. Detect Encoding Automatically Using chardet
When the encoding is unknown, use chardet to detect it.
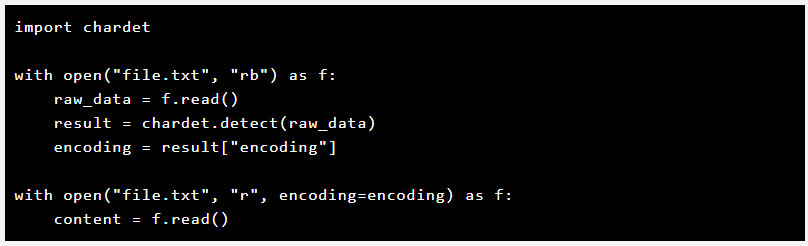
🔗 Learn more: chardet documentation
4. Convert File Encoding Using pandas
For CSV files, convert them to UTF-8 to maintain consistency.

🔗 More on pandas documentation.
5. Handle Byte Data Correctly
If dealing with binary data, manually decode it.

6. Use ftfy to Automatically Fix Broken Text
The ftfy library corrects text encoding issues.

🔗 Learn more: ftfy documentation
7. Utilize codecs for More Robust File Handling
For better encoding compatibility, use codecs.

8. Implement Universal Encoding Practices
- Ensure all files use UTF-8 encoding before processing.
- Use a consistent encoding format across all projects.
- Normalize text using libraries like
ftfyorunicodedata.
Common Real-World Scenarios of UnicodeDecodeError
- Web Scraping: Non-UTF-8 content can cause parsing issues.
- Log Files Processing: Different system encodings can break automation scripts.
- Multi-Language Applications: Incorrect encoding assumptions lead to data corruption.
How to Prevent UnicodeDecodeError in the Future
- Save and Read Files in UTF-8 – Set UTF-8 as the default encoding.
- Validate Encoding Before Processing – Use
chardetto detect encoding. - Handle Errors Gracefully – Use
errors="replace"orerrors="ignore"to prevent crashes. - Normalize Encoding Using
ftfy– Fix broken characters before further processing. - Use Proper File Conversions – Convert all project files to UTF-8 to ensure compatibility.
- Check File Encoding Before Processing – Use system commands:

🔗 More details in Python Unicode HOWTO
Conclusion
Handling UnicodeDecodeError is essential for smooth text processing. By using the correct encoding, handling errors gracefully, and detecting encoding automatically, you can prevent annoying crashes. Best practices like using UTF-8, detecting encoding before reading files, and normalizing text ensure robust Python applications.
Following this guide will help you master Python encoding and prevent UnicodeDecodeError from disrupting your workflow. 🚀 Happy coding!
FAQs on Python UnicodeDecodeError Fix
1. What is the difference between UnicodeDecodeError and UnicodeEncodeError?
UnicodeDecodeError occurs when Python fails to convert bytes to a string due to an incorrect encoding assumption. On the other hand, a UnicodeEncodeError happens when Python cannot convert a string to bytes in the specified encoding format.2. How does UTF-8 encoding help prevent UnicodeDecodeError?
3. Why does Python default to UTF-8 for text encoding?
4. Can changing the system locale settings affect UnicodeDecodeError?
5. Why do different operating systems cause UnicodeDecodeError?
UnicodeDecodeError may occur.6. What is the difference between ASCII and UTF-8 in handling text?
7. Can I fix UnicodeDecodeError without specifying an encoding?
errors="replace" or errors="ignore" can prevent crashes, but specifying the correct encoding is always the best solution.Conclusion
The Python UnicodeDecodeError Fix is essential for smooth text processing in Python. By specifying the correct encoding, handling errors properly, and using encoding detection tools like chardet, you can prevent decoding errors and improve your workflow.
💡 Got a tricky encoding issue? Drop a comment or explore more Python tips on our blog! 🚀


I am facing one issue related to python code e.g LOAD_GLOBAL instruction wrong source position. Can you please suggest to get this resolve error
ok, let me check is there any error SS please share …